Author Gender in Book Recommendations
I’m very pleased that we will be able to present a piece of research we have been working on for some time now at RecSys this year.
In my work on fair recommendation, one of the key questions I want to unravel is how recommender systems interact with issues of representation among content creators. As we work, as a society, to improve representation of historically underrepresented groups — women, racial minories, indigenous peoples, gender minorities, etc. — will recommender systems hinder those efforts? Will ‘get recommended to potential audiences’ be yet another roadblock in the path of authors from disadvantaged groups, or might the recommender aid in the process of exposing new creators to the audiences that will appreciate their work and make them thrive?
In this paper, we (myself, my students Mucun Tian and Imran Kazi, and my colleagues Hoda Mehrpouyan and Daniel Kluver) present our first results on this problem. This work, along with our work on recommender evaluation errors, formed the key preliminary results for my NSF CAREER proposal.
This paper has a few firsts for me. It’s my first fully-Bayesian paper, and is also the first time I have been able to provide complete code to reproduce the experiments and analysis with the manuscript submission.
, , , , and . 2018. Exploring Author Gender in Book Rating and Recommendation. In Proceedings of the 12th ACM Conference on Recommender Systems (RecSys ’18), Oct 3, 2018. ACM, pp. 242–250. DOI 10.1145/3240323.3240373. arXiv:1808.07586v1 [cs.IR]. Acceptance rate: 17.5%. Citations reported under UMUAI21. Cited 117 times.
Goal
In this project, we sought to understand how author genders are distributed in book ratings and in the resulting recommendations when those ratings are fed to a collaborative filter. We had three main questions:
- How prevalent are books by women in users’ book ratings? Effectively, what is the input data bias1 with respect to author gender? We also looked at gender distribution in the Library of Congress catalog as a baseline of ‘books published’ to provide context for interpreting user profiles.
- How prevalent are books by women in the recommendations users receive? In other words, how what is the overall bias of different recommender algorithms?
- How do the gender distributions of individual users’ recommendations relate to their rating profiles? Here, we are looking for the algorithms’ personalized bias: for an individual user, how do the recommendations respond to the input?
Data and Methods
We combined book rating data (from BookCrossing and Amazon) with library catalog data from OpenLibrary and the Library of Congress and author data from the Virtual Internet Authority File to build a book rating data set with attached author demographic information. Linking all the data together was an entertaining problem, but solvable with a few hundred gigabytes of SSD and PostgreSQL.
We then trained collaborative filters on the rating data and generated recommendation lists for a sample of users. We used a hierarchical Bayesian model to infer distributions of user rating behavior with respect to gender and to estimate the parameters of a linear model relating each recommender algorithm’s output to users’ input profiles. Our key variable of interest was ‘% Female’: of the books whose author’s gender we could identify, what percent are by women?
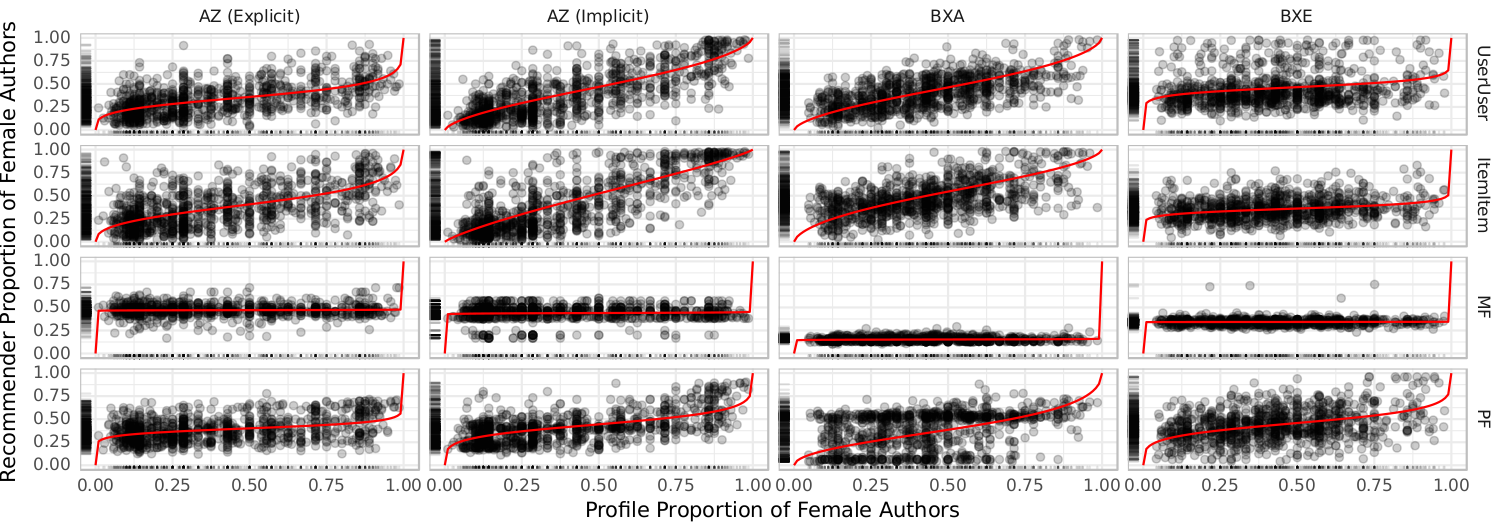
Results
Here are our key findings:
- Users are highly variable in their rating tendencies, with an overall trend favoring male authors but less strongly than the distribution in the Library of Congress catalog. If women are underrepresented in our set of published books, they are less underrepresented in users’ ratings.
- Algorithms differ in the gender distribution of their recommendations. Nearest-neighbor approaches were the most personalized in our data set, and their recommendations were comparable to the input data, though there was less variance between users’ recommendation lists than between their rating profiles.
- Nearest-neighbor algorithms were relatively responsive to their users’ profiles, with solid linear trends particularly in implicit feedback mode.
This is just the beginning — we have many more things planned in the coming years to build on these results and more thoroughly understand what recommender algorithms do in response to content creator representation.
Fun Statistical Tricks
This is the first paper I’ve published with a fully Bayesian analysis, a thing that pleases me greatly. We fit and sampled our distributions with Stan, letting us choose vague priors without concern for conjugacy and giving us good first-pass diagnostics for model fitting problems. It took some time to get it all working, but the end result was a pretty good experience.
We also used a logit-normal model for our proportions, and regressed on log odds instead of proportions. I’ve generally found odds and odds ratios difficult to intuit about, particularly compared to probabilities and proportions, but this project has helped me become more fluent in them.
If one of the outcomes of this line of work is learning to think natively in log-odds, I will be amused and also likely somewhat twisted.
Limitations
Our study has some important limitations. The algorithms are a small sampling of types of algorithm families, and trained on very sparse data, so the behavior may not be representative of their behavior in the wild.
The version of the work in this paper also uses a binary operationalization of gender. This comes up in two places: first, the underlying data is binary (all VIAF assertions of author gender are ‘male’, ‘female’, or ‘unknown’). This is a major problem, and it is a key limitation of this data set. The Library of Congress itself seems to do a better job in its authority records, but their coverage is smaller and we have not yet integrated their authority data into our pipeline (libraries tend to publish author records [authority data] and book records [bibliographic data] separately). The MARC Authority Format is flexible in its ability to encode author gender: the gender field is defined as gender identity, it uses open vocabularies, and it supports begin and end dates for the validity of a gender identity. The data we currently have available, however, does not make use of this flexibility.
Second, a proportion-based model reifies gender as a binary construct (although we could compute other proportions, such as ‘% Non-Binary’, if we had data that records such identities). We are currently working on addressing this problem by reframing the statistical model to perform what we are calling an author-perspective analysis: rather than looking at the proportion of a profile that is of a particular gender (), we are looking at the author’s likelihood of being rated given their gender. So far we have successfully fit a basic model for the overall book collection, and see comparable results. This model, once we have extended it through the rest of our analysis, will be more readily extensible to non-binary gender identities, as well as other non-binary identity frameworks such as ethnicity, than the proportion-based model.
Our approach in this work is to learn what we can with the data we have, while being forthright about the limitations and weaknesses of our data and methods and working to improve them for the next round of research.
Links and Next Steps
You can read a preprint of the full article with all the details on the paper’s web page; I will be updating that page with links to the official version once it is published, and the experiemnt and analysis code will be available as supplementary material with the published version in the ACM Digital Library. If the supplementary material winds up being paywalled, I will also mirror it at another location and provide a link on the paper page.
Our immediate next step is to finish improving our statistical model and perform some more analyses to better contextualize our findings; we hope to submit a revised version of the paper with these improvements for journal publication by the end of the year. After that, we have a lot of work to do to understand more aspects of recommender behavior, extend the work to additional demographic dimensions and item domains, and much, much more.
We use bias in the statistical sense, not in a moral sense. We do not know what ‘neutral’ is or should be; we are concerned with what the distribution is, and how the recommender responds to that distribution.↩︎